-
어플리케이션과 DB 간 I/O Holding성능 이슈 2020. 12. 21. 23:45
계정계 시스템의 트랜잭션 처리가 일시적으로, 그리고 간헐적으로 지연되는 현상에 대한 분석 사례이다.
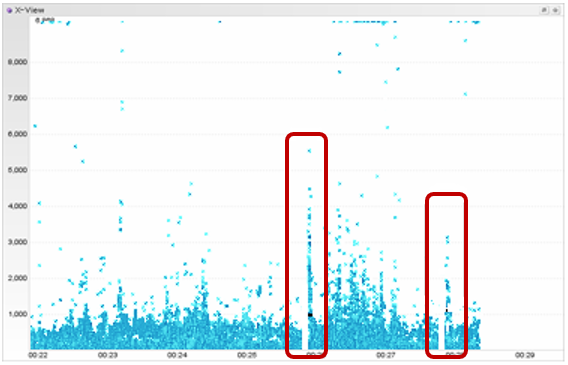
아래와 같이 APM (Application Peroformance Monitoring) 툴에서 보면, 일시적으로 트랜잭션이 전혀 처리되지 못한 채, 멈추는 현상이 간헐적으로 발생하고, 수 초 후 그간 적체됐던 요청들이 한 번에 처리되는 현상이다. (아래 그림은 임의 가공)
고객은 이를 애플리케이션의 요청이 DB에 전혀 기록되지 않았기에, 제목과 같이 애플리케이션과 DB 간 I/O가 홀딩되었다고 표현하였고, 그 원인이 스토리지에 있지 않나 하여 분석을 의뢰하였다.
Jennifer X-View 하기와 같이 분석 의견 전달
계정계 시스템의 트랜잭션 처리가 일시적으로 지연되는 현상에 대한 분석 의견을 드립니다.
먼저, 분석 대상 시스템에 대한 제한된 모니터링 및 데이터로 인한 한계가 있는 점 양해 바랍니다.
트랜잭션 처리 지연에 따라 순간적으로 응답 시간이 높게 나타나는 현상은 OLTP에서 흔히 관찰되고 있습니다.
다만, 그 원인이 다양하므로 그에 따른 적절한 대응을 해야 하는데, 과거의 경험을 반추해보면 다음과 같은 원인을 들 수 있으며, 정확한 분석을 위해서는 추가적인 노력이 필요할 것으로 판단됩니다.
아래 참조 바랍니다.
[발생 현상]
- APM (Jennifer)의 응답 시간 분포 화면(XVIEW)에서 일시적인 트랜잭션 처리 지연 및 적체 현상이 간헐적으로 나타남
- 일시적으로 처리가 안되었던 트랜잭션이 풀리면서 순간적인 응답 시간 급증이 나타남
- XVIEW 응답 시간이 Pillar 형태로 적체되는 시점에 DB active session 수가 높아지고, LGWR의 log file sync 시간도 높게 나타남
[주요 원인]
- WAS thread 및 Connection pool 부족
- Container의 Garbage Collection
- 애플리케이션의 로직 결함
- DML의 경합
- DBMS Bug
[분석 의견]
- WAS Parameter (Thread, connection pool) 점검 시 설정값이 50으로 여유 있고, Active 사용량도 매우 낮으므로 트랜잭션이 전혀 밀리지 않고 즉시 처리됨
- 특정 컨테이너의 GC 시 트랜잭션 처리가 지연될 수 있는 가능성을 확인하고자 다수를 대상으로 랜덤 체크한 결과, 전반적으로 전체 응답 시간과 동일한 패턴을 나타내므로 개별 Container의 문제는 아닌 것으로 보임
- OS (MCI, AP, DB)에서 측정한 I/O 현황은 트랜잭션 홀/기둥이 생기는 것과 무관하게 일정하고 반복적인 I/O를 기록하고 있으며, 간혹 튀는 구간이 있기는 하나 해당 현상과의 규칙성은 발견하지 못함
- AP, DB, MCI 서버에서 External disk에 1초 단위로 로그를 남긴 결과 I/O Pending 현상 없음
- AWR 상의 Sequence Lock이 보이긴 하나 Cache값 (1000)이 크기에 주요 원인은 아닌 것으로 보임
- Row lock 경합에 따른 실패 건수가 눈에 띔
- 이상과 같이 점검한 결과 OS, WAS, Storage의 문제는 아닌 것으로 판단됨
- 결국, 정확히 어떤 응용프로그램이 수행될 때 해당 현상이 생기는지 찾아야 하며, 아래와 같이 방향을 제시함
[향후 진행 방안]
- 제니퍼 프로파일링 설정을 통해 추적 가능
- 먼저 범위를 좁혀가는 것이 효율적이므로 계정계가 아닌 타 시스템과 외부 시스템을 호출하는 메서드 추가 (풀 클래스명+메서드명 등록)
- 튀는 응답 시간을 보고 로직에서 걸린 것인지, DB에서 걸린 것인지 판단
- 타 시스템, 외부 시스템도 아니라면 계정계에서 의심되는 메서드를 등록하여 파악
- 혹, 제니퍼에서 스레드 덤프가 남았는지 확인 후 덤프 분석 필요 (기본이 Thread 80개가 넘으면 자동으로 dump 생성되나, 80개에 도달하지 않았으면 수치 조정 필요)
[종합 의견]
제공된 로그를 분석한 결과 OS나 WAS의 원인은 아닌 것으로 보입니다.
결국, 어떤 애플리케이션이 수행될 때, 무슨 이유로 나타나는지를 밝혀야 하는데, 해당 XVIEW상의 패턴은 Lock 점유가 발생하고 어떤 조건이 만족하면 Lock을 풀어주는 메커니즘을 사용할 경우에 Lock 대기를 하는 애플리케이션에서 쉽게 발견할 수 있으며, 보통 병목으로 인한 영향은 특정 몇 개의 애플리케이션에 한정적입니다.
DB에서 다양한 DML이 중첩되어 Update를 위한 Lock wait이 발생할 경우 해당 Table이나 Row에 접근하려는 애플리케이션 또는 과도한 Synchronized block을 사용하는 애플리케이션에서도 자주 나타납니다.
예를 들어, J2EE Server에서 성능 향상을 위해 Cache를 적용할 경우 Cache에 대한 Update(clear/put/get) 과정에서의 Lock 대기로 발생하는 경우가 대표적이며, 자바에서 synchronized를 사용한 경우 해당 트랜잭션이 종료될 때까지 다른 트랜잭션은 대기할 수밖에 없으므로 그동안 처리를 못하게 되는 경우가 있을 수 있습니다.
어쨌든, 정확한 원인 분석을 위해서는 위에서 말씀드린 대로 APM 프로파일링을 통해 찾아내는 것이 효과적이고 빠른 방법입니다. 그러기 위해서는 응용팀과의 Cowork이 필요합니다.
경험상 오라클이나 벤더에서는 이러한 작업까지는 핸들링하기 어렵기에 전문 조직의 도움을 받는 것도 고려해보시기 바랍니다.
Ps.
타 사이트의 유사했던 사례는, HWM (High Water Mark) 관련 문제로 Table Shrink 후 이런 현상 해소된 적 있으며, 결국, Oracle Patch로 해결하였음
'성능 이슈' 카테고리의 다른 글
시스템 오픈후 성능 문제 발생을 최소화하기 위한 방안 (0) 2021.05.09 하드웨어 (CPU) 증설 후 스토리지 성능 저하 (0) 2020.12.31 HCI로 가상화 전환 후 VM 성능 이슈 (0) 2020.12.20 NAS 스토리지 간 파일 복제 시 inode 변경? (0) 2020.12.19 올플래시 스토리지로 교체 후 DB 성능 저하 현상 (0) 2020.12.17